

NORDTRANS Hybrid press conference (closing event)
14 Mar 2024

On Thursday 14th March 2024, a major development in speech technology was unveiled by a collaborative effort between Czech and Norwegian experts. A press conference held in Trondheim, Norway, and broadcasted online, showcased the results of an international partnership between NEWTON Technologies, a Prague-based company, Technical University of Liberec, also based in Czechia, and Norwegian University of Science and Technology in Trondheim (NTNU).
The NORDTRANS project, “Technology for automatic speech transcription in selected Nordic languages”, presented in this closing event also benefited from a 1.2 mil. € grant from Norway and Technology Agency of the Czech Republic.
As the main outcome of the project, the joint team developed state-of-the-art quality speech recognition technology for transcribing speech to text in Norwegian, Swedish, and Danish. According to final testing, the NORDTRANS modules outperformed global competitors in accuracy of transcription in all three Nordic languages.

“On average our models outperform the competitors by a significant margin; by several percents absolutely in Danish and Swedish, while in Norwegian there is a smaller, if positive, difference in the average results,” explains Petr Červa from TUL, one of the lead researchers in the project.
All of these highly accurate language modules have been integrated into the Beey platform by NEWTON Technologies, making them readily available to users worldwide for various use cases, from video subtitling, meeting minutes, and conference transcripts, to automatic summarization and further processing with a variety of AI tools.
“We all read and hear about large language models, which are mainly based on written language. Most digital content, though, is in audio or video format: up to two thirds of all internet traffic is video, which virtually always has an audio component. If you can take this spoken content and convert it into written form, then you can unleash the power of AI on pretty much everything,” comments Alessandro Cederle from NEWTON Technologies on the impact of speech-to-text technology on the new AI wave in the digital world.
Find out more about this closing event at the link below.
NORDTRANS Press conference
24 Nov 2022

NEWTON Technologies held a press conference on 24 November 2022 to introduce the project and the development of speech technologies for Nordic languages, including a demonstration of its use in practice in the Beey application.
The meeting took place at NEWTON Technologies offices in Prague. Lenka Weingartová, Principal Investigator of the project, presented on behalf of the organizers. Furthermore, Petr Červa and Jan Nouza from the Technical University of Liberec, and especially our guests from NTNU – Janine Rugayan and Torbjørn Svendsen, presented their research activities. The entire presentation was held in English.
Presenting the NORDTRANS project as an example of good practice
20 Sep 2022

On 20 September, NEWTON Technologies attended a meeting about our implementation of the EEA and Norway Grants. Lenka Weingartová introduced the NORDTRANS project, in which along with the Technical University of Liberec we are developing technology for automatic speech-to-text transcription for Norwegian (and eventually Swedish).
We are proud to have been selected from twenty other projects in the Research category to present the Norwegian recognition module as an example of good practice in the use of Norway Grants. In addition, we were also pleased that the Ambassador of the Kingdom of Norway and other representatives of the Norwegian Embassy in Prague attended the meeting and saw a live demonstration of Norwegian in the Beey app.
Scandinavian language identification at the Text, Speech and Dialogue 2021 Conference
10 Sep 2021
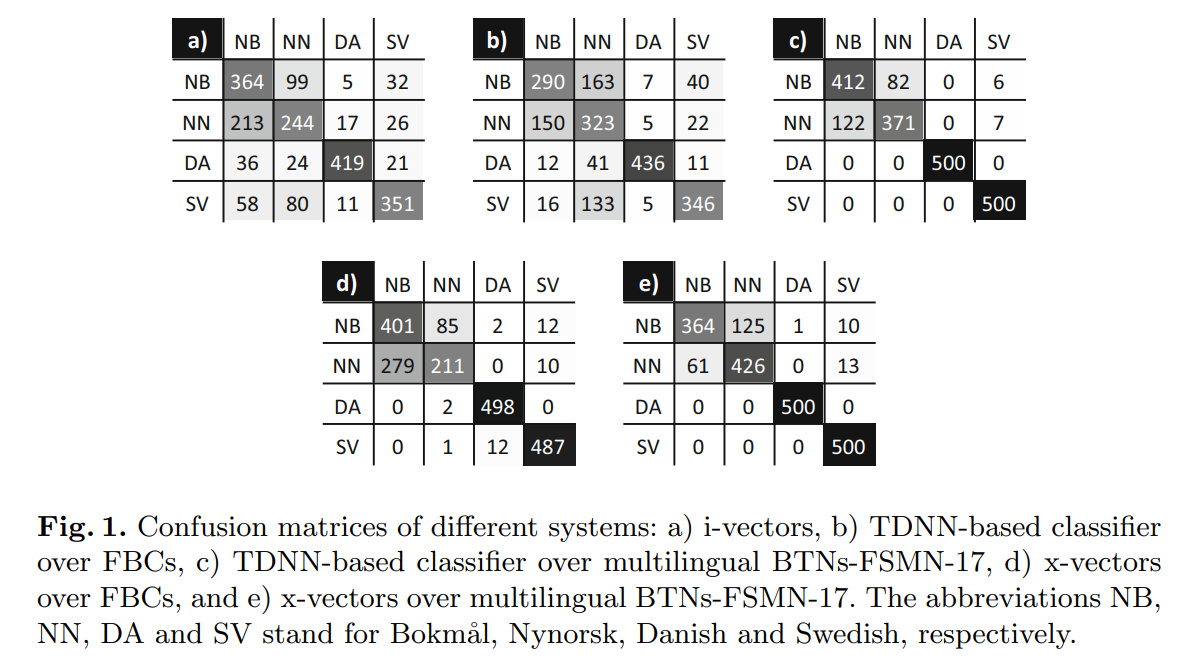 The team of Petr Červa and Jan Nouza presented a paper called “Identification of Scandinavian Languages from Speech Using Bottleneck Features and X-vectors” at the Text, Speech and Dialogue Conference in Olomouc.
The team of Petr Červa and Jan Nouza presented a paper called “Identification of Scandinavian Languages from Speech Using Bottleneck Features and X-vectors” at the Text, Speech and Dialogue Conference in Olomouc.
The paper deals with identification of the three main Scandinavian languages (Swedish, Danish and Norwegian) from spoken data. The best resulting approaches take advantage of multilingual bottleneck features (BTNs) and allow us to identify the target languages in speech segments lasting only 5 seconds with a very low error rate around 1%. The identification offers the opportunity for many practical applications, such as in systems for transcription of Scandinavian TV and radio programs, where different persons speaking any of the target languages may occur.
Norwegian now available in Beey
11 Aug 2021
The first version of automatic Norwegian transcription is now available in Beey. Beey is a web-based platform designed for automatic transcription of recordings and its fast editing.
Norwegian thus becomes the first commercially available Nordic language in the portfolio of NEWTON Technologies.
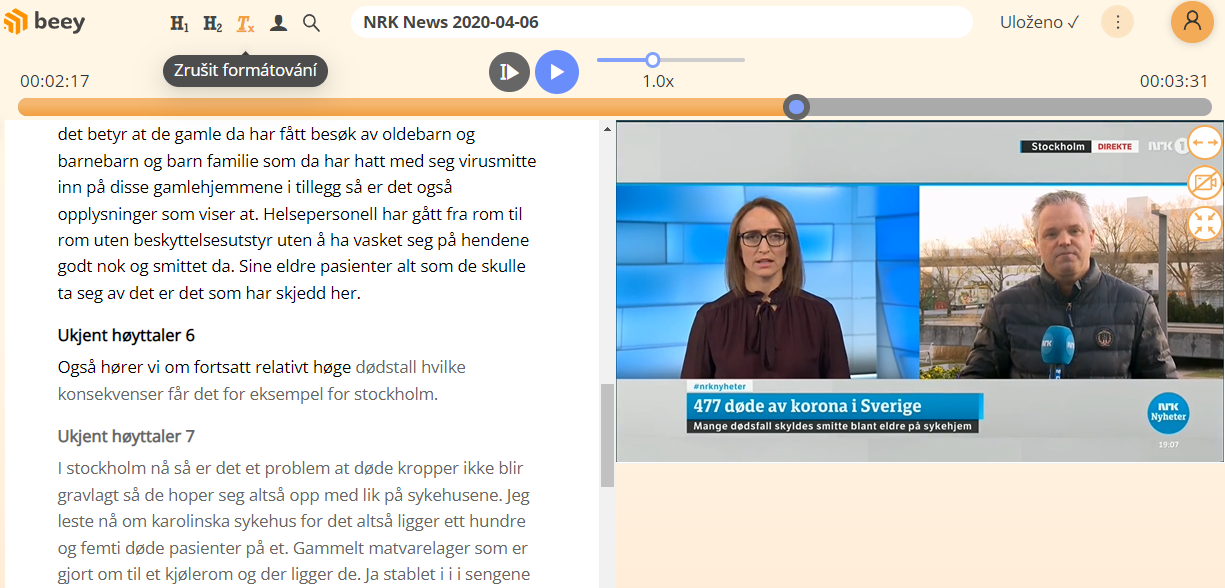 The acoustic model is trained on 210 hours of recordings collected from various publicly available sources, such as the Norwegian TV NRK, Norwegian radio and transcripts of parliamentary proceedings.
The acoustic model is trained on 210 hours of recordings collected from various publicly available sources, such as the Norwegian TV NRK, Norwegian radio and transcripts of parliamentary proceedings.
The automatic transcription of Norwegian can handle both written variants, Bokmål as well as Nynorsk, even in the case when speakers switch between the two.
Interview with Lenka Weingartová in the Meltingpot forum
28 May 2021
The principal investigator of the NordTrans project, linguist Lenka Weingartová, was a guest of the Meltingpot Forum. In an interview with moderator Vladimír Piskala, they talked about how to teach a computer to understand human speech and the projects NEWTON Technologies is currently involved in, including the NordTrans project, and the pitfalls of Scandinavian language recognition.